

| 제목 | [기술정보] 초거대AI 데이터 품질관리 가이드라인 |
|---|
| 분류 | 성장동력산업 | 판매자 | 전아람 | 조회수 | 55 | |
|---|---|---|---|---|---|---|
| 용량 | 7.78MB | 필요한 K-데이터 | 13도토리 |
| 파일 이름 | 용량 | 잔여일 | 잔여횟수 | 상태 | 다운로드 |
|---|---|---|---|---|---|
| 7.78MB | - | - | - | 다운로드 |
| 데이터날짜 : | 2024-04-05 |
|---|---|
| 출처 : | 국책연구원 |
| 페이지 수 : | 102 |
추진 배경
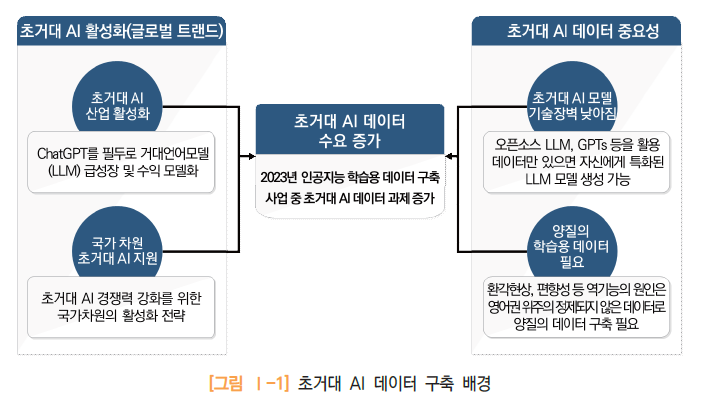
초거대 AI 데이터 구축 중요성 증대
- 글로벌 빅테크 기업들의 초거대 AI 투자 및 모델 공개 등으로 초거대 AI 산업 급성장에 따라
초거대 AI 데이터를 구축하여 민간에 개방함으로써 AI산업 생태계 활성화 및 지원 필요
- 아부다비의 Falcon 180B, 중국의 Yi-34B (0.1 AI) 등 국가 차원의 초거대 AI 지원 흐름에 발맞춰
우리나라 또한 ‘초거대 AI 경쟁력 강화 방안’(2023.4, 디지털플랫폼정부) 전략 수립 및 데이터 확충 지원
- 초거대 AI의 환각현상, 편향성 등 역기능이 발생하는 주요 원인은 정제되지 않은 데이터, 영어권
위주의 데이터 학습이 주요 원인으로 국가별 언어의 특성을 살린 양질의 데이터 확보 필요
- 다양한 오픈소스 기반 초거대 AI(sLLM 등) 모델 개방 및 서비스를 통해 초거대 AI에 관한 기술
장벽이 낮아져 누구나 데이터만 있으면 자신에게 특화된 GPT 모델을 생성 가능한 시대로 전환
- 앞서 기술한 사유들로 인한 초거대 AI 데이터의 수요 증가로 ‘2023년 학습용 데이터 구축 사업’
중 초거대 AI 데이터 구축 과제 증가에 따라 체계적인 품질관리 정책 마련 필요
초거대 AI 데이터 품질관리 체계 수립 필요
- 초거대 AI 데이터 관점의 품질관리 역량 확보를 위한 품질관리 방법 및 절차의 체계적 접근 필요
- 초거대 AI 데이터는 기존의 지도학습용 데이터와 다른 고유의 특징 보유
⦁초거대 AI 데이터는 매우 거대한 데이터(구축량) 필요
⦁초거대 AI 학습용 말뭉치 데이터는 자기지도학습(Self Supervised Learning)으로 사전학습을
수행하여 기존의 지도학습 데이터와 달리 라벨링이 없거나 부분적으로 수행(필수적이지 않음)
⦁공정 단계별로 구축되는 지도학습용 데이터와 달리 초거대 AI 데이터는 사전학습된 기반
모델(Foundation Model)을 다양한 방법으로 반복하여 조정하는 구축 절차를 수행하며,
학습(Training)/검증(Validation)/테스트(Test) 데이터의 유형도 다양한 양상을 보임
- 이에 따라, 초거대 AI 데이터 구축을 위한 별도의 품질관리 체계 및 구체적인 가이드라인 제시 필요
---------------------------------------------------------------------------------------------------------------------------------
※ 본 서비스에서 제공되는 각 저작물의 저작권은 자료제공사에 있으며 각 저작물의 견해와 DATA 365와는 견해가 다를 수 있습니다.