

| 제목 | [정책분석] 인공지능 학습을 위한 자연어 데이터 가공단계의 품질검수 기준 |
|---|
| 분류 | 성장동력산업 | 판매자 | 나혜선 | 조회수 | 39 | |
|---|---|---|---|---|---|---|
| 용량 | 187.5KB | 필요한 K-데이터 | 5도토리 |
| 파일 이름 | 용량 | 잔여일 | 잔여횟수 | 상태 | 다운로드 |
|---|---|---|---|---|---|
| 187.5KB | - | - | - | 다운로드 |
| 데이터날짜 : | 2024-01-08 |
|---|---|
| 출처 : | 국책연구원 |
| 페이지 수 : | 6 |
1. 머리말
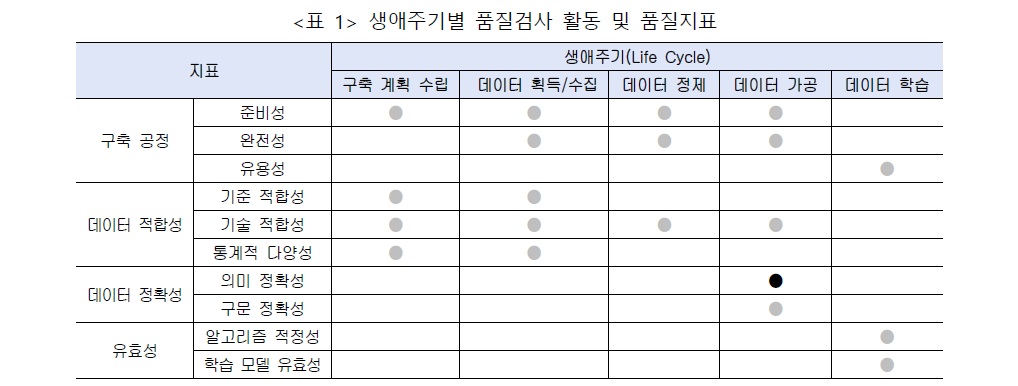
인공지능 학습용 데이터의 구축 및 활용이 증가함에 따라 데이터 구축 과정을 기반으로 데이터 의 생애주기(Life Cycle) 관점에서 데이터 품질관리가 필요하다. 인공지능 학습용 데이터 구축 공 정 과정에서 확보된 품질은 학습데이터 전체의 품질을 결정한다. 특히 데이터 가공단계에서 기 계학습에 활용할 수 있도록 기능이나 목적에 부합하는 라벨링 작업을 수행하는데, 인공지능 모 델의 성능 평가에 중요한 영향을 미치는 참값(Ground Truth) 등의 라벨링 정보의 정확성이 확보 되는 수준으로 가공 작업이 이루어져야 한다.
또한 인공지능 전문 연구 기관들의 데이터 가공 및 검수 기준 도입을 통해 데이터 품질수준을 한층 높은 수준으로 끌어올릴 수 있으나, 전문연구 기관들의 데이터 품질검증 기준은 연구 목적 에 부합하도록 가공 및 검수의 기준을 정하고 있어 일반 다수 사용자들이 데이터를 활용하거나 적용하기에는 품질기준의 복잡도가 높다.
더구나 인공지능 학습용 데이터는 특정 인공지능 모델의 학습을 목적으로 생산되는 데이터이므 로 임무 정의에 따라 구축되는 특성을 가지며, 그 특성은 가공 단계의 라벨링 작업을 통해 데이 터에 반영된다. 따라서 라벨링의 의미적인 측면이 인공지능 모델의 임무 정의에 정확하게 부합 하고 있는지 검증해야 하며, 이는 인공지능 학습을 위해 유효한 데이터와 더불어 인공지능 모델 의 임무 수행에 대한 성능 결과와 직결된다.
본고에서는 한국어 음성 및 텍스트 데이터를 대상으로 인공지능의 기능과 목적에 부합하는 요구 사항을 충족할 수 있도록 품질검증 항목을 중심으로 데이터 가공 단계에서의 품질검수 기준을 제시한다.
----------------------------------------------------------------------------------------------------------------------------------------------------
※ 본 서비스에서 제공되는 각 저작물의 저작권은 자료제공사에 있으며 각 저작물의 견해와 DATA 365와는 견해가 다를 수 있습니다.