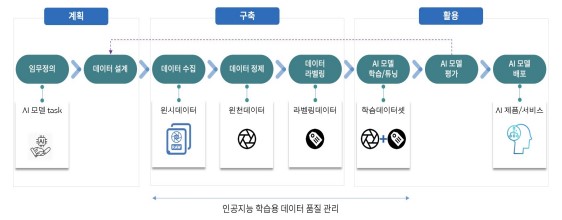
인공지능이 전 산업 분야로 확산하면서 머신러닝을 통해 여러 가지 제품이나 서비스에 인공지능을 활용하게 되었다. 머신러닝은 컴퓨터 시스템과 프로그램이 인간의 직접적인 도 움이나 개입 없이 인간의 인지 과정과 유사한 방식으로 문제를 해결하기 위해 학습한 예측 결과를 활용하는 것으로서 “코드로서 명령하지 않은 동작을 데이터로 학습하고 기계가 실행 하도록 알고리즘을 개발하거나 연구하는 분야”로 정의할 수 있으며[1], 지도 학습, 비지도 학습, 강화학습으로 분류할 수 있다. 머신러닝은 방대한 데이터를 처리하고 특정 작업을 수 행하기 위한 패턴을 인식하도록 훈련되며, 인간과 마찬가지로 더 많은 학습을 통해 인공지능 이 수행해야 하는 임무(task)를 더 잘 할 수 있게 된다. 따라서 특정한 임무를 수행할 수 있도록 인공지능을 훈련시키기 위해서는 수행할 임무에 대한 훈련을 위해서 지도학습 관점 에서 인공지능 학습용 데이터가 필요하다. 고품질의 인공지능 학습용 데이터는 머신러닝의 성능을 향상시키는데 핵심적인 요소이다. 분류와 회귀 같은 지도 학습이나 추천 시스템에서 높은 성능을 내려면 정답 정보가 포함된 데이터나 말뭉치, 사전처럼 양질의 학습용 데이터가 많이 필요하다[2]. 이미지 인식, 음성 인식, 기계 번역 등 다양한 분야에서 인공지능에서 성과 를 거두게 된 것은 인공지능 알고리즘의 발전과 이를 뒷받침하는 컴퓨팅 리소스 등으로 가능 해졌지만 무엇보다 대량의 인공지능 학습용 데이터셋이 있어서 가능했던 일이기도 하다. 그런데, 인공지능 연구 개발 과정에서 주요 병목 현상은 더 이상 알고리즘이나 하드웨어에서 발생하지 않고 의미 있는 작업을 해결하기 위해 충분한 인공지능 학습용 데이터셋을 만드는 것에서 발생하고 있다