

| 제목 | [산업분석] 분산 딥러닝 학습 플랫폼 분석 |
|---|
| 분류 | 성장동력산업 | 판매자 | 정한솔 | 조회수 | 95 | |
|---|---|---|---|---|---|---|
| 용량 | 1.8MB | 필요한 K-데이터 | 7도토리 |
| 파일 이름 | 용량 | 잔여일 | 잔여횟수 | 상태 | 다운로드 |
|---|---|---|---|---|---|
| 1.8MB | - | - | - | 다운로드 |
| 데이터날짜 : | 2023-04-03 |
|---|---|
| 출처 : | 국책연구원 |
| 페이지 수 : | 24 |
[개요]
분산 딥러닝 학습 플랫폼 기술은 TensorFlow와 PyTorch 같은 Python 기반 딥러닝 라이브러리를 확장하여 딥러닝 모델의 학습 속도를 빠르게 향상시키는 분산 학습 솔루션입니다. 분산 딥러닝 학습 플랫폼은 Soft Memory Box(소프트웨어)의 공유 메모리 버퍼를 비동기적인 분산 딥러닝 파라미터 통신을 위해 사용함으로써 분산 학습 시간을 단축합니다.
- 소프트 메모리 박스(Soft Memory Box: SMB)는 분산 딥러닝용 파라미터 고속 통신을 위한 분산 공유 메모리 버퍼(Shared Memory Buffer)를 제공합니다. SMB는 Infiniband 네트워크 기반 소프트웨어로 다수의 서버들의 메모리를 통합하여 딥러닝 파라미터 통신을 위한 버퍼로 제공합니다. 제공되는 공유 메모리 용량은 제한 없으며 메모리 서버 대수와 각 메모리 서버의 제공 메모리 용량에 따라 가변적입니다. 제공되는 공유 메모리 대역폭 또한 메모리 서버의 대수와 Infiniband 대역폭에 종속됩니다. 메모리 서버를 많이 이용할수록 대역폭은 증가합니다. (예, 97GiB w/ 8 Servers, Infiniband HDR 기준)
- EDDIS(SW)는 TensorFlow와 PyTorch 딥러닝 모델의 고속 분산 학습을 지원하는 프레임워크입니다. 소프트 메모리 박스가 제공하는 공유 메모리 버퍼를 기반으로 딥러닝 모델의 고속 분산 학습을 제공합니다. 기존 다중노드 동기식 파라미터 업데이트 기법을 사용하는 Horovod 및 PyTorch DDP 대빙하여 EDDIS는 동일한 개수의 GPU를 사용할 때 이종 GPU 환경에서 모델에 따라 2배 이상 빠른 학습 성능을 제공합니다(16Node, 64 GPUs, Tensorflow Resnet50 2.5배, PyTorch Yolov5 2.3배). TensorFlow, PyTorch 모델을 EDDIS API로 리팩토링하여 분산학습을 진행할 수 있으며, CNN, RNN 및 그 외 DNN 모델을 지원합니다. EDDIS는 데이터 병렬 동기식/비동기식/하이브리드 방식 분산 학습을 지원합니다.
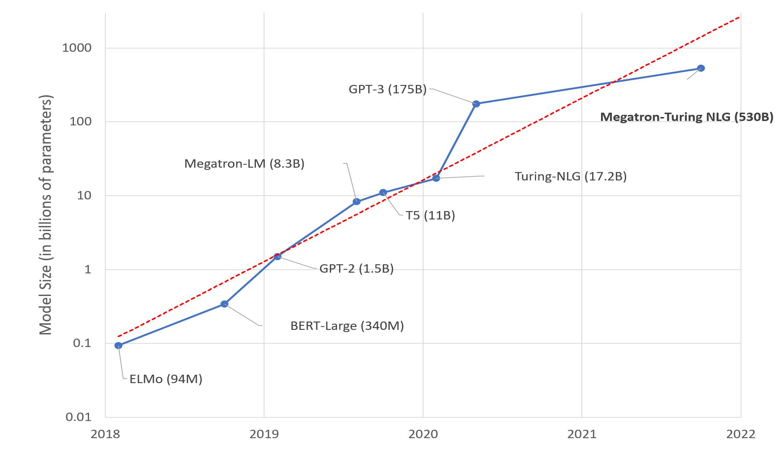
- (현황) 딥러닝 기술은 높은 정확도를 요구하는 모델일수록 더 많은 학습데이터와 더 높은 해상도의 학습 데이터를 요구(예, 고해상도 영상 처리 요구 증가). 더 높은 정확도를 가지는 모델은 기하급수적인 계산량 증가를 수반하며, HPC 시스템을 이용하여 대규모 딥러닝 모델을 분산 학습하려는 수요가 증가하고 있음
- (통신병목 문제점) 다수의 서버를 이용한 딥러닝 분산 학습은 대규모 통신이 필요하여 통신 병목이 발생하며, 이를 해결하는 고속 분산 병렬 학습 기술이 필요함. 더욱이 서버의 수를 늘릴수록 통신 병목 현상이 심화되어 학습 시간이 서버의 수 만큼 선형적으로 개선되지 않는 문제 해결이 필요함. 또한 대다수 딥러닝 개발자들은 고성능 컴퓨팅 시스템, 병렬처리, 분산 처리등에 대한 지식과 경험부족으로 상기 문제 해결에 어려움을 겪고 있음.
- (GPU 이종화 문제점) 급격한 기술발달로 GPU 자원의 이종화 파편화는 심화되고 있으며, 동종의 최고사양 GPU(예, Nvidia Tesla A100)로 구성되는 클러스터의 구축에는 매우 많은 투자비가 요구되어, 일부 대기업을 제외한 대부분의 기업/학교/연구소에서는 소규모 이종화된 GPU 서버로 딥러닝 모델을 개발하는 실정이며, 또한 오픈소스 딥러닝 라이브러리들은 동종 GPU에 특화된 학습 기법을 사용하므로, 다양한 세대별 GPU들로 구성되는 이종 성능의 GPU 서버들을 효과적으로 사용할 수 있는 기술 필요
- (통신병목, 이종자원 문제 해결) 본 기술은 분산 학습시 발생하는 통신 병목의 문제를 해결하고, 이종 GPU 클러스터 운영시의 비효율성을 해결하여, 딥러닝 응용을 개발하고자 하는 기업, 대학, 연구소 등의 기관들이 대규모 딥러닝 학습데이터를 딥러닝 모델로 학습할 때 비용 효율적인 방법으로 적시에 딥러닝 서비스 개발을 지원하고자 함.
※ 본 서비스에서 제공되는 각 저작물의 저작권은 자료제공사에 있으며 각 저작물의 견해와 DATA 365와는 견해가 다를 수 있습니다.