

| 제목 | [산업분석] 2025년 온디바이스 생성형 AI 최적화 기술과 경량 모델 확산 전망 |
|---|
| 분류 | 성장동력산업 | 판매자 | 장민환 | 조회수 | 81 | |
|---|---|---|---|---|---|---|
| 용량 | 605KB | 필요한 K-데이터 | 8도토리 |
| 파일 이름 | 용량 | 잔여일 | 잔여횟수 | 상태 | 다운로드 |
|---|---|---|---|---|---|
| 605KB | - | - | - | 다운로드 |
| 데이터날짜 : | 2025-08-28 |
|---|---|
| 출처 : | 국책연구원 |
| 페이지 수 : | 16 |
I. 서론
불과 2년 남짓한 사이에 생성형 AI는 우리 삶 곳곳에 깊숙이 자리 잡았다. ChatGPT는 이제 검색 대신 대화라는 새 습관을 만들었고
카약 및 익스페디아에서는 사용자의 소셜 미디어 콘텐츠를 기반으로 여행 일정을 자동으로 제시한다[1].
엔지니어 10명 중 9명이 코드 작성에 AI 도구를 쓰며, 깃허브 코파일럿 사용자는 1년 만에 1,500만 명을 넘어섰다
[2]. 갤럭시 S25 등 최신 안드로이드 스마트폰은 제미니 나노를 기본 탑재해 오프라인 환경에서도 사진 요약이나 음성 녹취 정리를
수행한다[3]. 이처럼 생성형 AI는 여행ㆍ개발ㆍ모바일까지 없어서는 안 될 인프라로 비중이 급격히 커지고 있다.
II. 트랜스포머 모델 최적화 기술 동향
2017년 구글이 처음 제시한 트랜스포머 모델은 입력 프롬프트의 길이를 획기적으로 늘임과 동시에 병렬 연산에 적합한 구조로
수십억~수조 개의 파라미터로 이루어진 거대언어 모델의 기반이 되었다[9]. 이를 기반으로 생성형 AI의 크기가 기하급수적으로
증가함에 따라 트랜스포머 모델 추론에 소모되는 비용 또한 급격하게 증가하였고, 이를 해결 하기 위해 트랜스포머 모델 최적화
연구가 활발하게 이루어지고 있다. 본 장에서는 트랜스포머 모델에 대한 주요 최적화 기술들에 대해 알아본다.
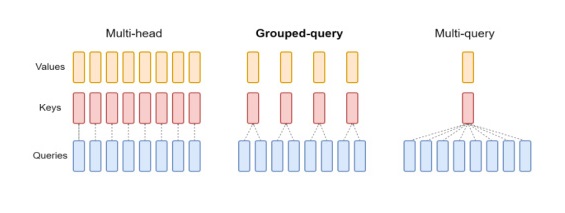
1. 어텐션 최적화 기술
KV(Key/Value) 캐싱은 이미 계산한 어텐션 값은 캐시에 저장해 다시 계산하지 않는 최적화 기법이다[9].
트랜스포머 디코더 내 셀프 어텐션 구조는 토큰을 하나씩 생성할 때 매번 이전 모든 토큰과의 어텐션 값에 대한 계산이 필요하다.
KV 캐싱은 이런 이전 토큰의 KV 행렬을 캐시에 저장해 두었다가 이후에 재사용함으로써 불필요한 연산을 방지한다.
---------------------------------------------------------------------------------------------------------------------------------------------------------
※ 본 서비스에서 제공되는 각 저작물의 저작권은 자료제공사에 있으며 각 저작물의 견해와 DATA 365와는 견해가 다를 수 있습니다.